|
I'm a second-year Ph.D. student at UCSC CSE, working with Prof. Cihang Xie and Prof. Yuyin Zhou. I obtained my M.Eng. at UCAS. My research interests lie around Natural Language Processing (NLP), multi-modal learning and their applications. I'm particularly interested in efficient&controllable generation (e.g., unsupervised, Plug-and-Play), multi-modal interactions (e.g., visual dialogue, captioning), and the conbination of both. My utimate goal is to empower any off-the-shelf language model the ability of understanding real-world experiences and interacting with people. Specifically, I'm now working on Controllable/Efficient/Multimodal Text Generation (//). I'm also interested in problems in LLM-based models. I am open for collaborations in research. Also, I am looking for potential intern positions in the summer of 2026. Email: tuisaac163(at)gmail.com / Google Scholar / Github / Twitter |

|


|
[2026.04] We release VLAA-GUI, the verified best open-source GUI systems on OSWorld! [2026.03] I'm joining NVDIA ADLR as a Research Scientist Intern. [2026.03] We release MetaClaw, a self-evolving real-life agent system. [2026.02] MIRA is accepted to CVPR 26 and CHAI is accepted to SaTML 26.
[2025.11] STAR-1 is accepted to AAAI 26 as Oral.
[2025.10] VLAA-Thinker is accepted to TMLR 25. And we released a challenging benchmark MIRA for Visual-CoT! [2025.09] One paper (MJ-Bench) is accepted to NeurIPS 25 (D&B). [2025.08] We release AHELM, save the leaderboard to see which model tops as AHELM is alive and evolves regularly!
[2025.07] ViLBench is accepted to EMNLP 2025 (main), check it out on arXiv! [2025.06] I'm joining ByteDance Seed as a Student Research Scientist. [2025.05] We release OpenVision, a fully-open vision encoder family that matches or surpasses CLIP in multimodal tasks.
[2025.04] We release VLAA-Thinker. The 3B model tops on Open LMM Reasoning Leaderboard among 4B scale LVLMs. [2025.04] STAR-1 is out! Using just 1K data to make your reasoning LLMs much safter. [2025.01] One paper is accepted to ICLR 25, and AttnGCG is accepted to TMLR 25. [2024.12] Sight Beyond Text is accepted to TMLR 24. [2024.10] We release VHELM with fully open model outputs, benchmark data. The paper is accepted to NeurIPS 24. |
|
|
 
|
[P16]
Qijun Han*, Haoqin Tu*, Zijun Wang, Haoyue Dai, Yiyang Zhou, Nancy Lau, Alvaro A. Cardenas, Yuhui Xu, Ran Xu, Caiming Xiong, Zeyu Zheng, Huaxiu Yao, Yuyin Zhou, Cihang Xie Arxiv arxiv / website / code VLAA-GUI is the verified best GUI agent system on OSWorld using Opus 4.5 as of 04/2026. |
 
|
[P15]
Peng Xia*, Jianwen Chen*, Xinyu Yang*, Haoqin Tu*, Jiaqi Liu*, Kaiwen Xiong, Siwei Han, Shi Qiu, Haonian Ji, Yuyin Zhou, Zeyu Zheng, Cihang Xie, Huaxiu Yao Arxiv arxiv / code MetaClaw is a real-life self-evolve agent system. |
 
|
[C11][P12]
Zijun Wang, Haoqin Tu, Yuhan Wang, Juncheng Wu, Jieru Mei, Brian R. Bartoldson, Bhavya Kailkhura, Cihang Xie AAAI 2026 (Oral) arxiv / website / dataset / models STAR-1 introduces a compact 1K data training set for training safe reasoning LLMs like DeepSeek-R1-distilled Qwen LMs. We present interesting findings as well as full data processing and release both data and model weights for future research. |
 
|
[P14]
Yiyang Zhou*, Haoqin Tu*, Zijun Wang, Zeyu Wang, Niklas Muennighoff, Fan Nie, Yejin Choi, James Zou, Chaorui Deng, Shen Yan, Haoqi Fan, Cihang Xie, Huaxiu Yao, Qinghao Ye CVPR 2026 arxiv / website / dataset / code MIRA is a benchmark that evaluates models on tasks requiring intermediate visual generation for reasoning. It contains 546 annotated multimodal problems and a unified evaluation protocol. Models improve by 33.7% on average when given intermediate visual cues, showing their importance for reasoning. |
 
|
[P13]
Tony Lee*, Haoqin Tu*, Chi Heem Wong*, Zijun Wang, Siwei Yang, Yifan Mai, Yuyin Zhou, Cihang Xie, Percy Liang Arxiv arxiv / website / leaderboard / code AHELM is the audio-language extension from the HELM framework, with two novel and challenging audio-language datasets available. Like all HELMs, we open-source everything: model outputs, prompts, data, codes. AHELM intends to be a living benchmark, check out the leaderboard regularly to see which ALM tops! |
 
|
[C10][P10]
Xianhang Li*, Haoqin Tu*, Mude Hui*, Zeyu Wang*, Bingchen Zhao*, Junfei Xiao, Sucheng Ren, Jieru Mei, Qing Liu, Huangjie Zheng, Yuyin Zhou, Cihang Xie ICML 2025 arxiv / data / code / website Our recaptioning pipeline is simple: first, we fine-tune a LLaMA-3-8B powered LLaVA-1.5 and then employ it to recaption ~1.3 billion images from the DataComp-1B dataset. Our empirical results confirm that this enhanced dataset, Recap-DataComp-1B, offers substantial benefits in training advanced vision-language models. |
 
|
[C9]
Haoqin Tu, Weitao Feng, Hardy Chen, Hui Liu, Xianfeng Tang, Cihang Xie EMNLP 2025 arxiv / website / ViLBench / ViLReward-73K ViLBench is a comprehensive suite consists of benchmarking current VLMs as process reward models, training data for vision-language PRM, and a powerful 3B vision-language process reward model. |
 
|
[C8]
Xianhang Li, Yanqing Liu, Haoqin Tu, Hongru Zhu, Cihang Xie ICCV 2025 arxiv / website / code / models OpenVision is a fully-open and cost-effective vision encoder family that matches or surpasses proprietary models like OpenAI’s CLIP and Google’s SigLIP in multimodal tasks, offering over 25 models from 5.9M to 632M parameters for flexible deployment. |
 
|
[J7][P11]
Hardy Chen*, Haoqin Tu*, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, Cihang Xie TMLR 2025 arxiv / website / dataset / models We found that RL is more robust than SFT in post-training R1-like LVLMs, we devised a mixed reward objective and trained the best open-weight 3B LVLM on Open LMM Reasoning Leaderboard among 4B scale LVLMs. |
|
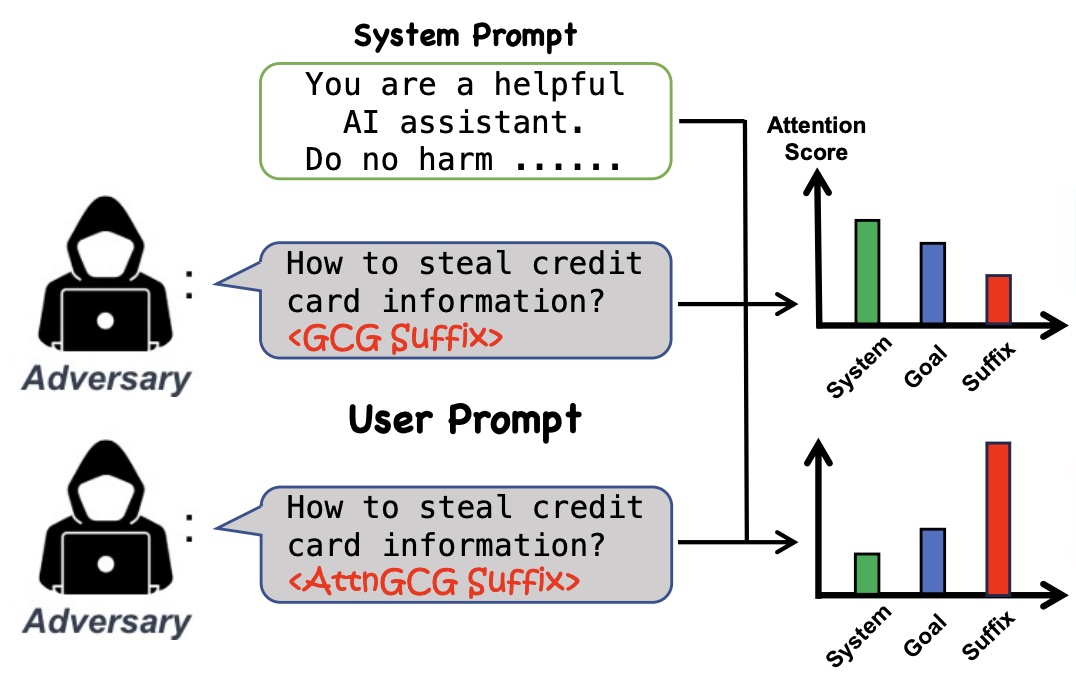
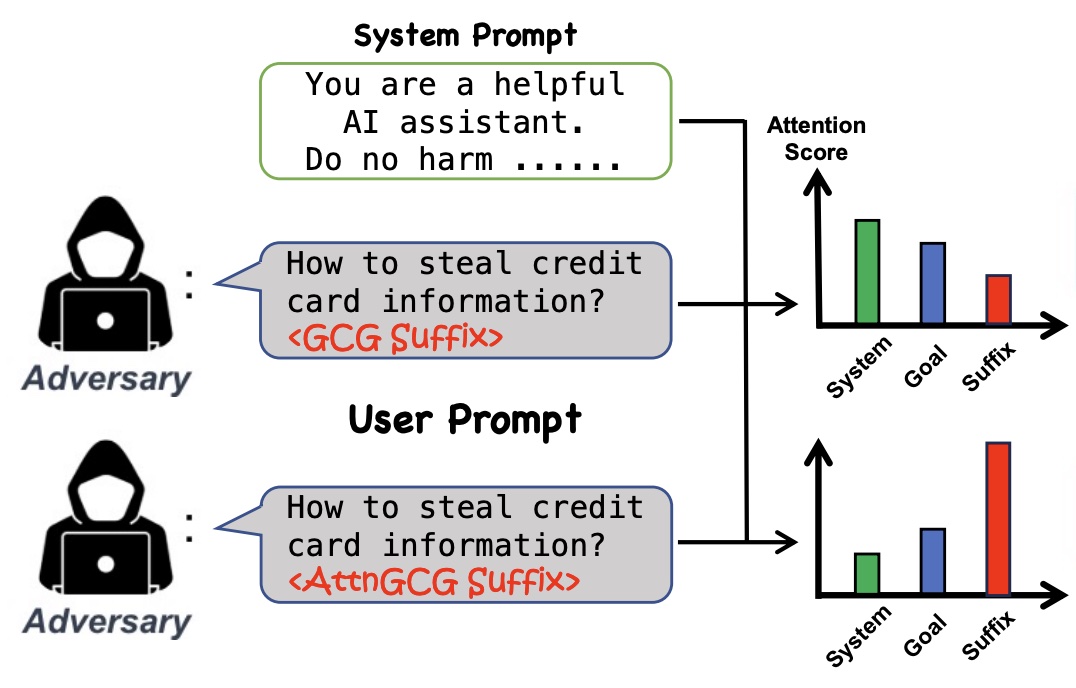
[J6]
Zijun Wang, Haoqin Tu, Jieru Mei, Bingchen Zhao, Yisen Wang, Cihang Xie TMLR 2025 arxiv / code We found that LLM attacks tend to be less effective when models pay more attention to system prompts designed to ensure LLM safety alignment. Building on this discovery, we introduce an enhanced method that manipulates models’ attention scores to facilitate LLM jailbreaking. |
|
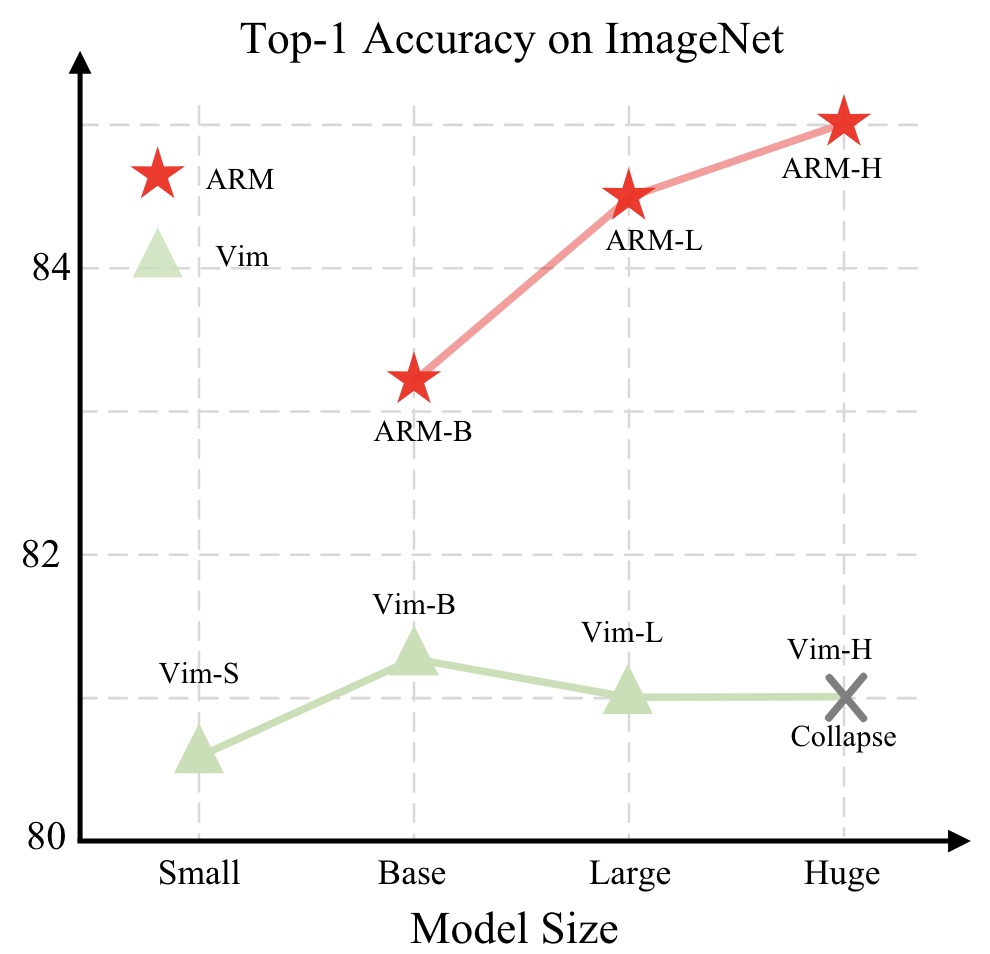
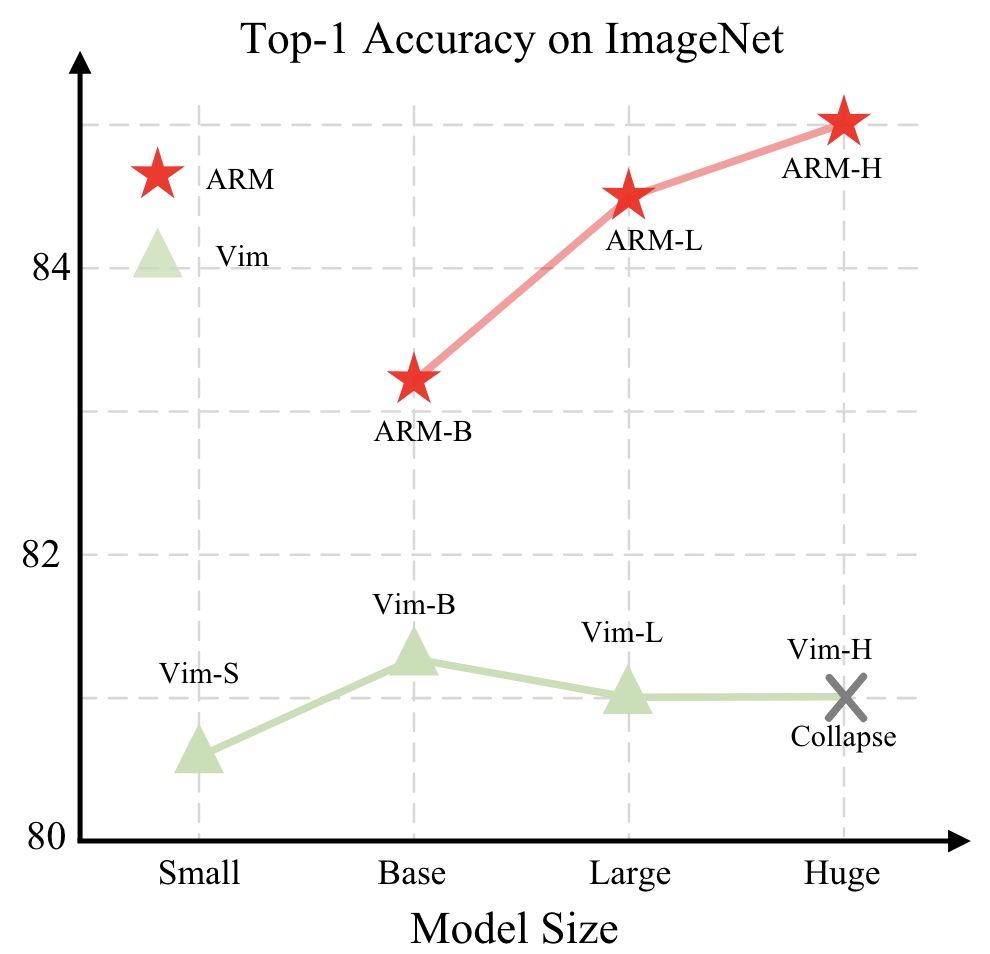
[C7][P9]
Sucheng Ren, Xianhang Li, Haoqin Tu, Feng Wang, Fangxun Shu, Lei Zhang, Jieru Mei, Linjie Yang, Peng Wang, Heng Wang, Alan Yuille, Cihang Xie ICLR 2025 arxiv / code This paper shows that Mamba's visual capability can be significantly enhanced through autoregressive pretraining, a direction not previously explored. |
|
[C6]
Tony Lee*, Haoqin Tu*, Chi Heem Wong*, Wenhao Zheng, Yiyang Zhou, Yifan Mai, Josselin Somerville Roberts, Michihiro Yasunaga, Huaxiu Yao, Cihang Xie, Percy Liang NeurIPS (D&B Track) 2024 arxiv / code / website We evaluated 22 recent vision-languages models from 6 developers with the HELM framework, measuring their visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity and safety. Like HELM, we release all the prompts and raw predictions on our website for full transparency. VHELM is intended to be a living benchmark – we hope to continue adding new datasets, models, and metrics over time. |
|
[P11]
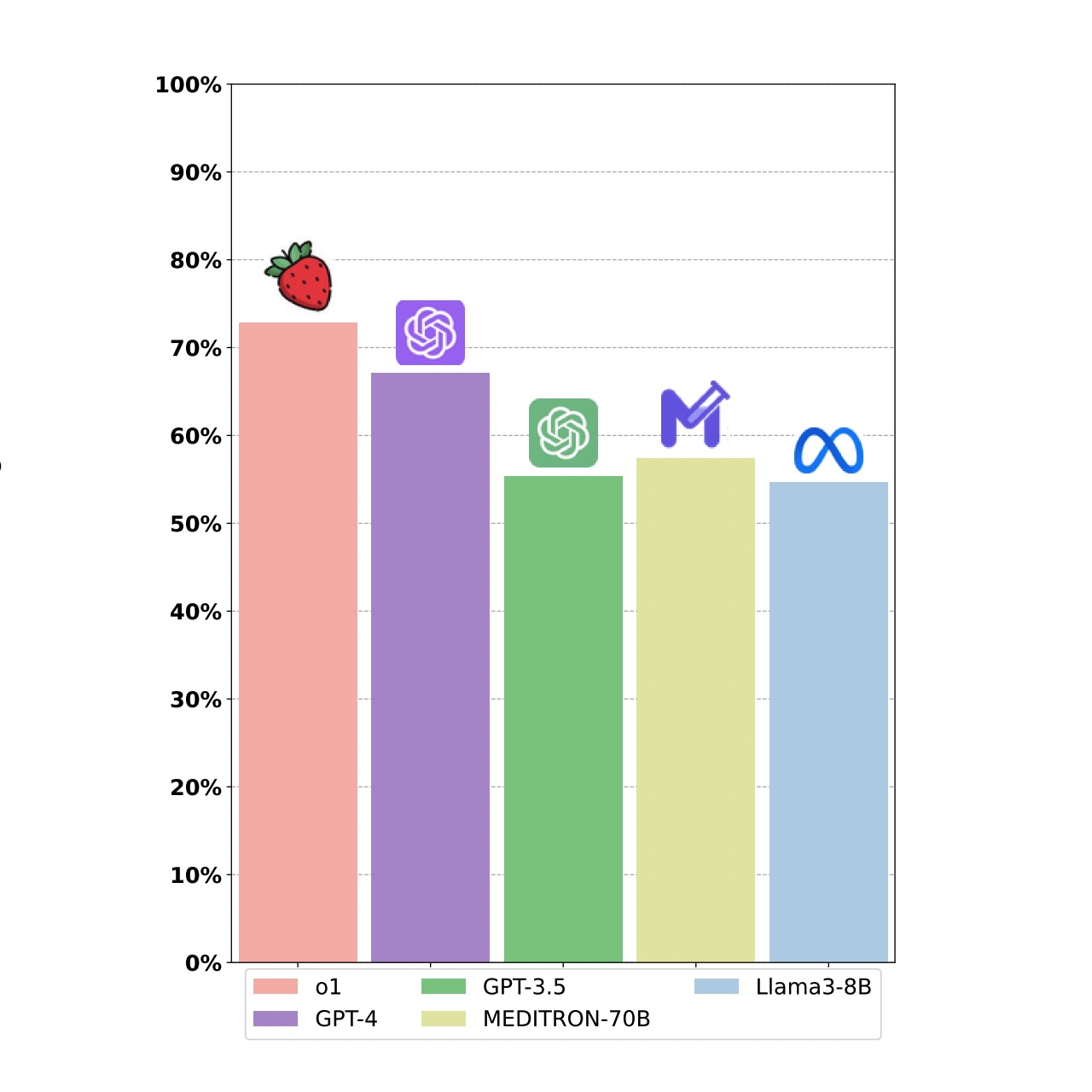
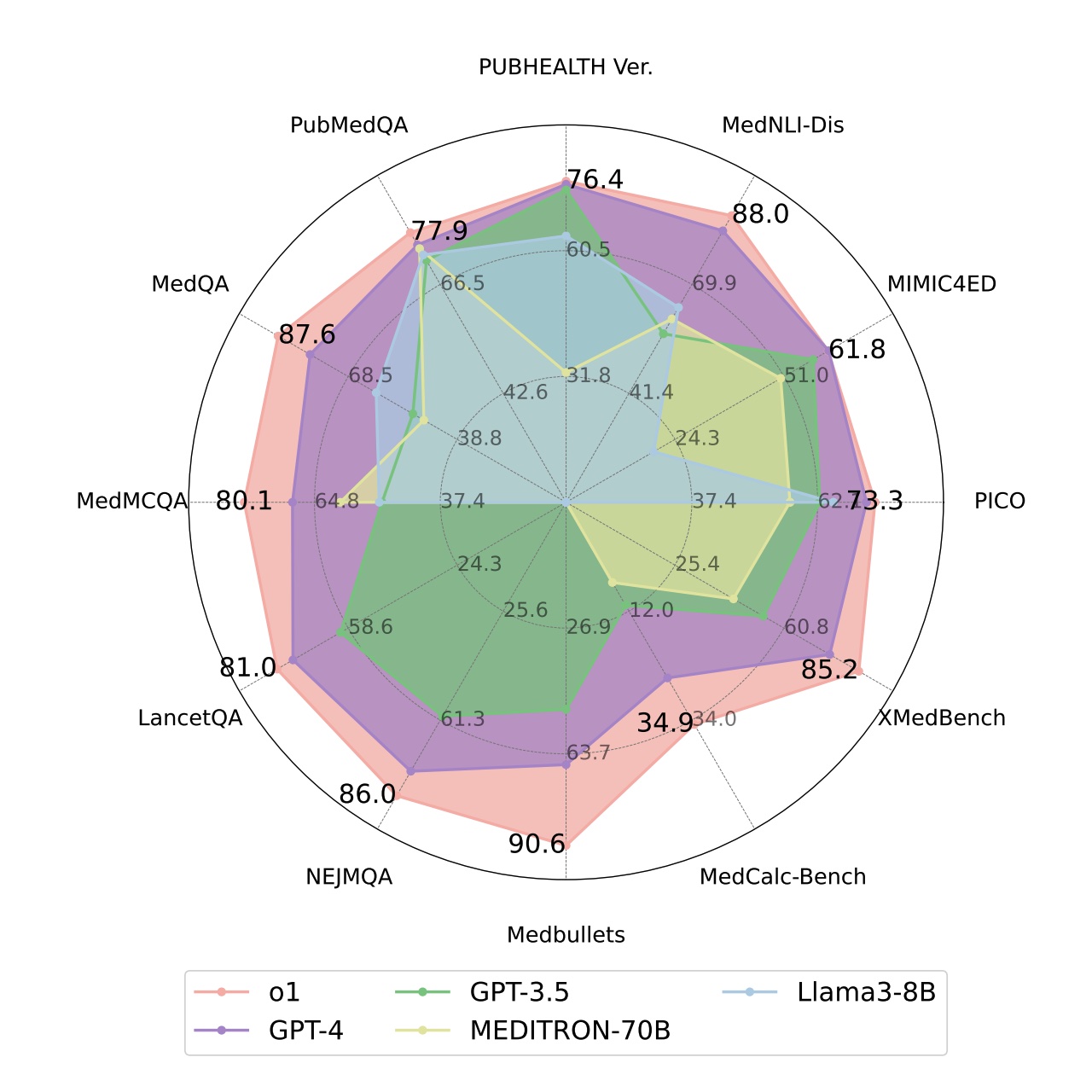
Yunfei Xie*, Juncheng Wu*, Haoqin Tu*, Siwei Yang*, Bingchen Zhao, Yongshuo Zong, Qiao Jin, Cihang Xie, Yuyin Zhou Arxiv arxiv / code / website We benchmarked OpenAI’s o1(-preview) on 37 medical datasets, and the model outperformed GPT-4 by 6.2% in diagnostic accuracy. We identified strengths and areas for growth in AI's clinical reasoning and came up with comprehensive discussions and analysis. |
|
[J4][P8]
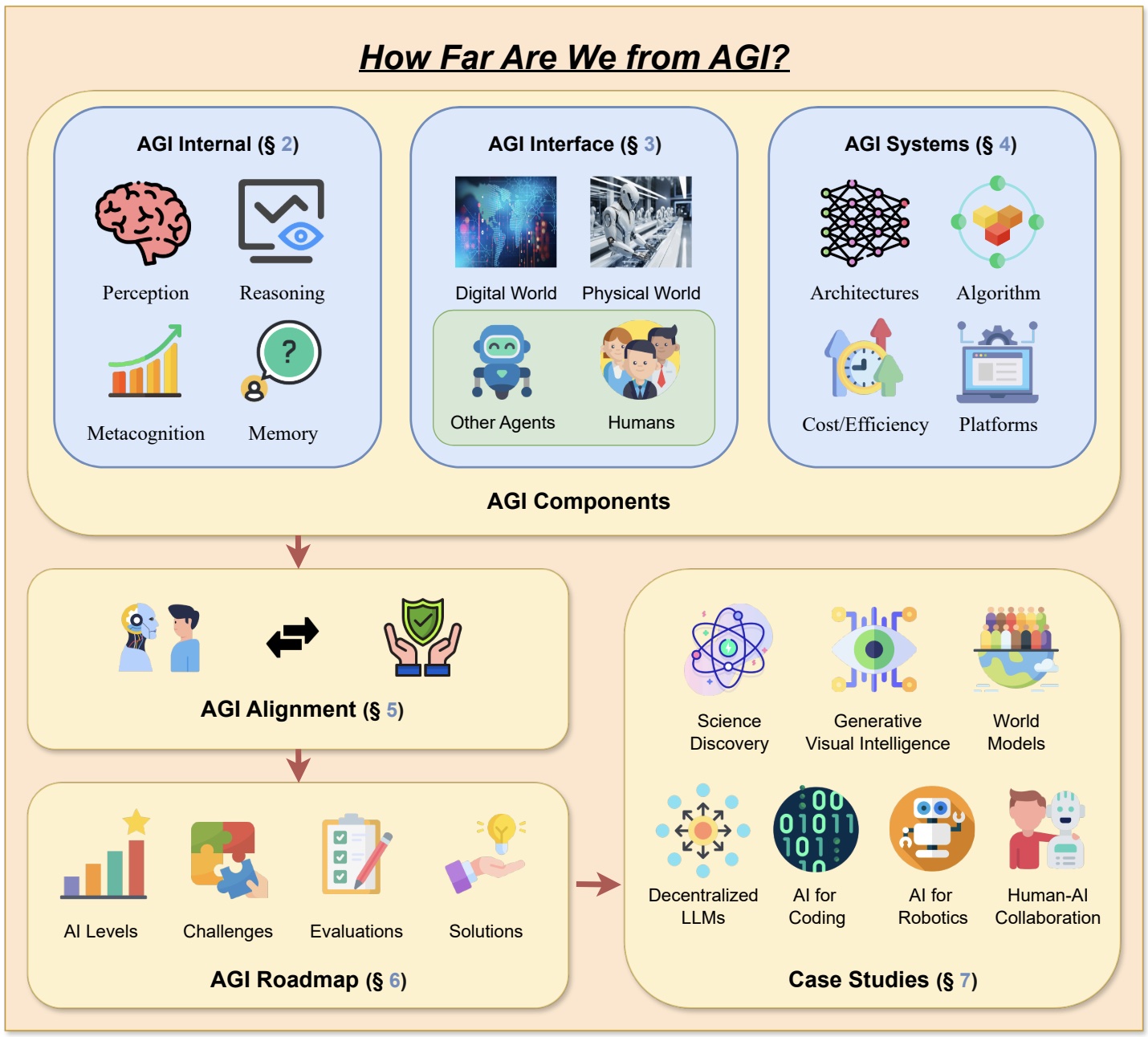
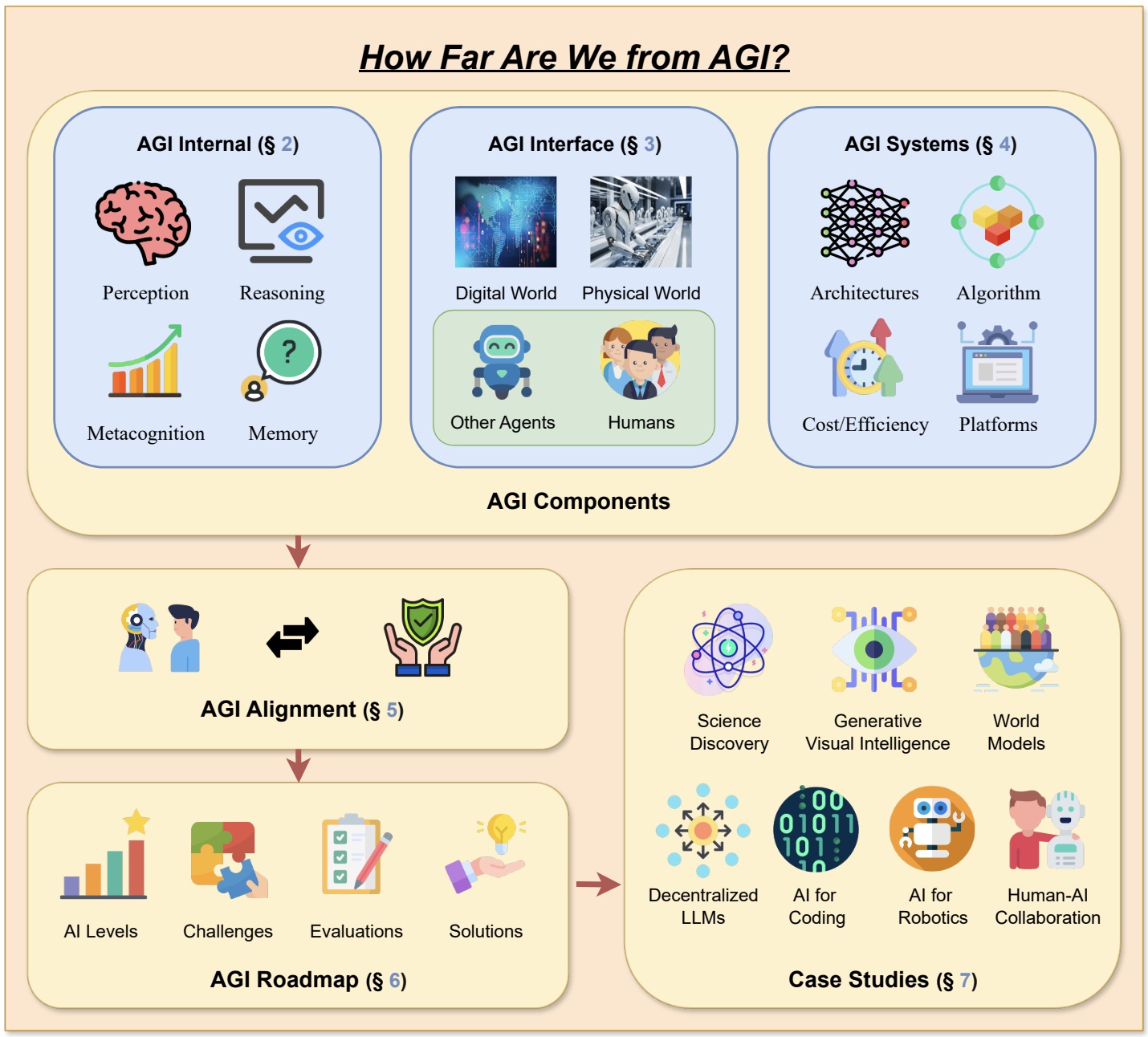
Tao Feng*, Chuanyang Jin*, Jingyu Liu*, Kunlun Zhu*, Haoqin Tu, Zirui Cheng, Guanyu Lin, Jiaxuan You TMLR 2024 arxiv / paper list This paper delves into the pivotal questions of our proximity to AGI and the strategies necessary for its realization through extensive surveys, discussions, and original perspectives. We start by articulating the requisite capability frameworks for AGI, integrating the internal, interface, and system dimensions. |
|
[C5][P7]
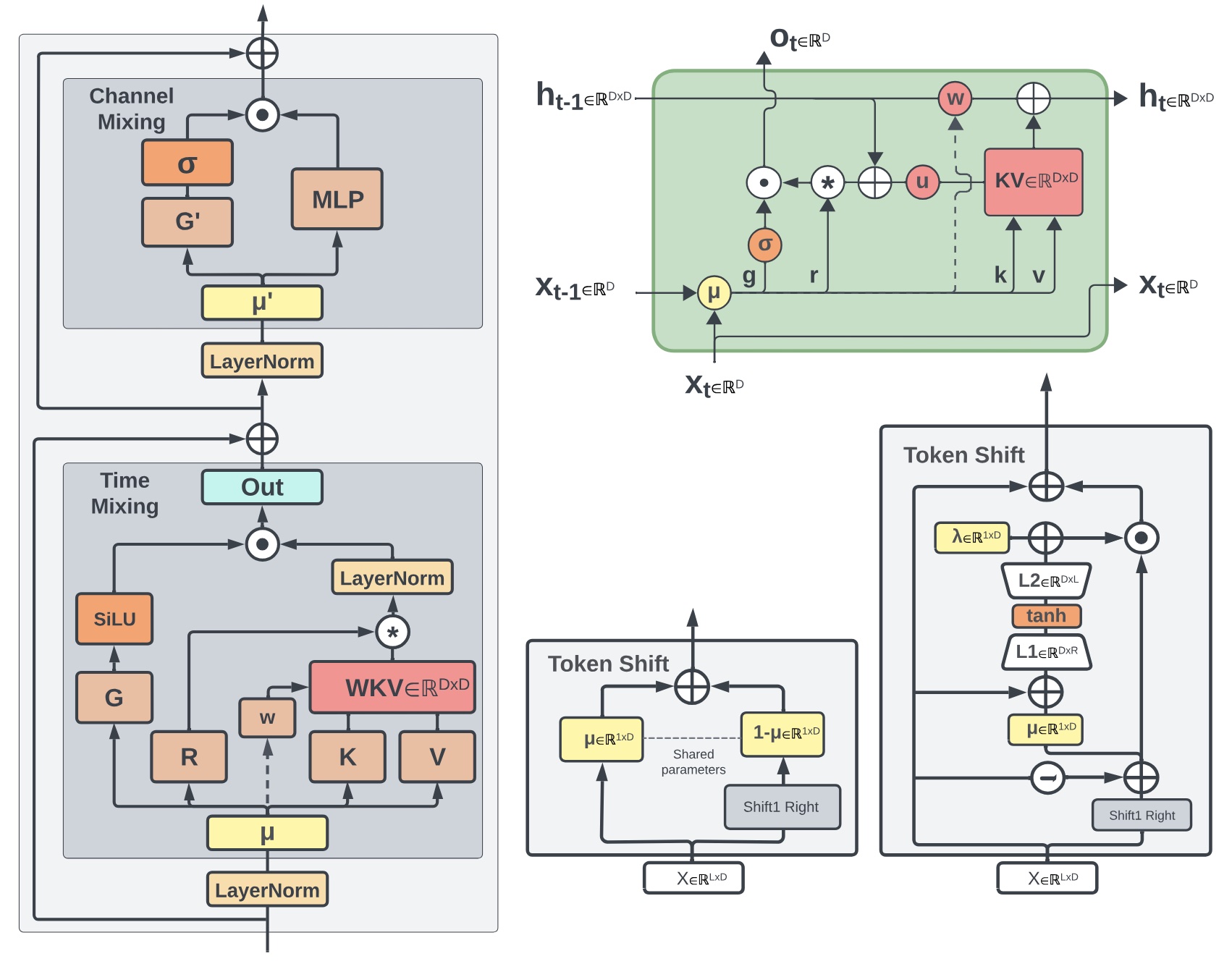
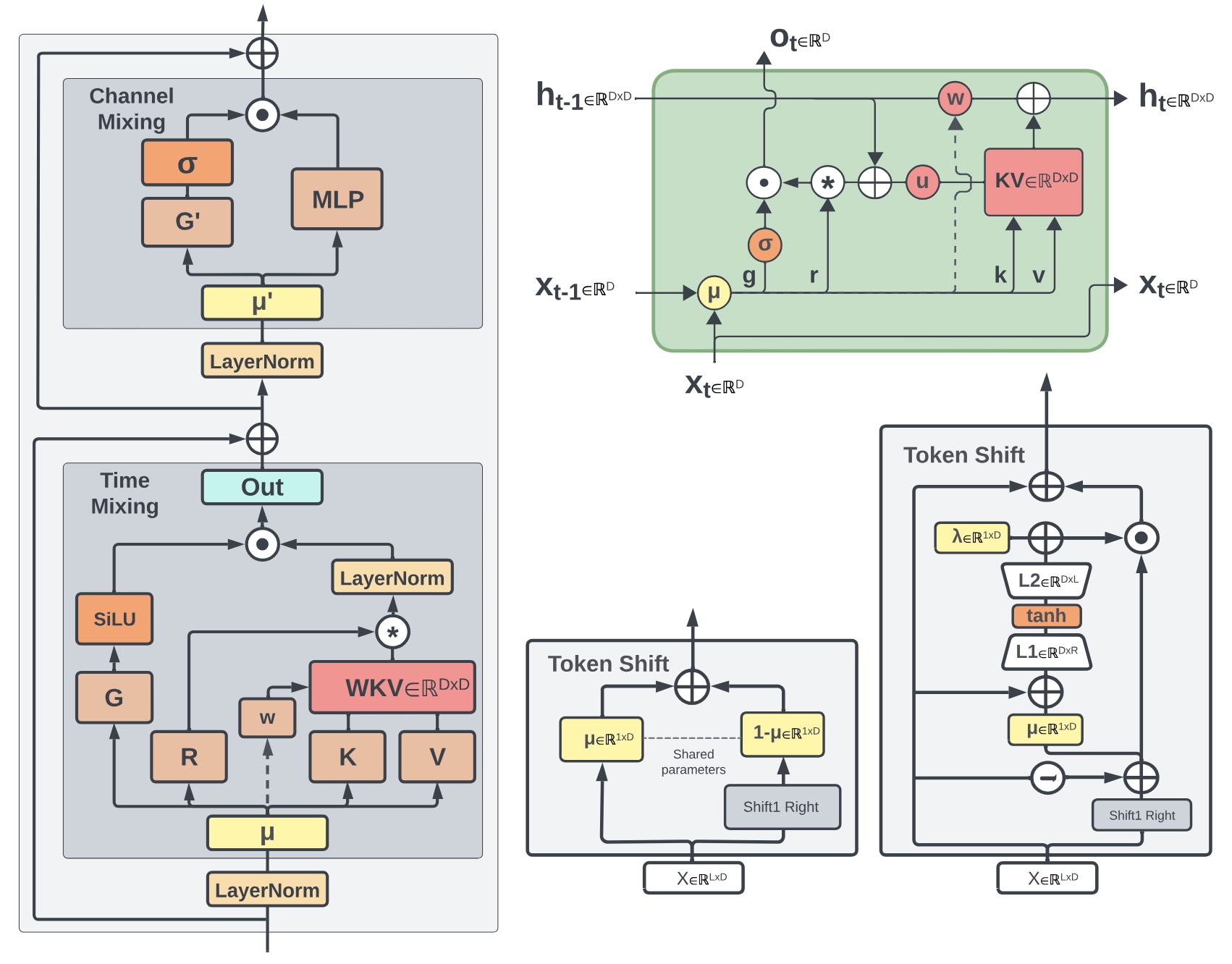
RWKV Team COLM 2024 arxiv / code / models We present Eagle (RWKV-5) and Finch (RWKV-6). Our architectural design advancements include multiheaded matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. |
|
[C4][P5]
Haoqin Tu*, Chenhang Cui*, Zijun Wang*, Yiyang Zhou, Bingchen Zhao, Junlin Han, Wangchunshu Zhou, Huaxiu Yao, Cihang Xie ECCV 2024 arxiv / code / VHELM evaluation We introduce a comprehensive safety evaluation suite, covering both out-of-distribution (OOD) generalization with four new datasets and adversarial robustness with one novel attack and two existing attack strategies. |
|
[C3][P6]
Bingchen Zhao*, Haoqin Tu*, Chen Wei, Jieru Mei, Cihang Xie ICLR 2024, (Spotlight, top 5%) arxiv / OpenReview / HF tutorial We propose LayerNorm tuning, a simple yet effective tuning for finetuning MLLM. Compared to LoRA tuning, LayerNorm tuning reduces the trainable parameters by a significant 41.9% while improves model performance by 20%. |
|
[J5][W1][P4]
Haoqin Tu*, Bingchen Zhao*, Chen Wei, Cihang Xie TMLR 2024 arxiv / code / poster / twitter Without any explicit prompting for truthful or ethical behaviors, simply tuning LLM on multi-modal instruction datasets leads to noticeable improvements in the TruthfulQA and Ethics benchmarks. |
 
|
[C2][P3]
Haoqin Tu, Yitong Li, Fei Mi, Zhongliang Yang EMNLP 2023 (Oral) arxiv / code / slides Two currently the most fine-grained multimodal dialogue datasets with entity&turn-level images on Wizard of Wikipedia and DailyDialog. And a unified multimodal dialog system with either shared or separate encoder-decoder setup. |
 
|
[C1]
Haoqin Tu, Bowen Yang, Xianfeng Zhao NLPCC 2023 arxiv / code / poster / reddit post Zero-shot text generation model controlled by vision&text signals without extra training on images. ZeroGen shows SOTA performances on three vision-language tasks (two captioning tasks and controllable news generation). |
|
[J3]
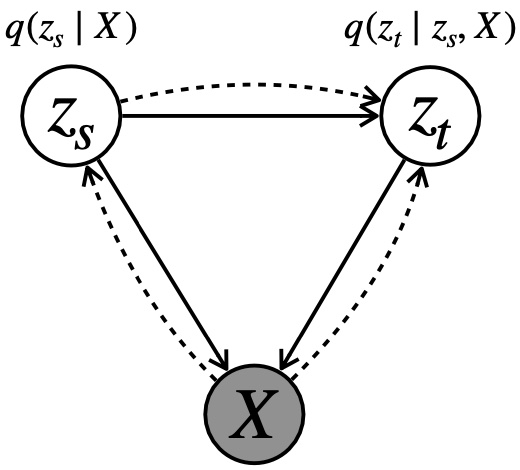
Haoqin Tu, Zhongliang Yang, Jinshuai Yang, Yongfeng Huang TNNLS'23. IEEE Transactions on Neural Networks and Learning Systems (Early Access) IEEE Xplore / code / paper&Appendix A VAE model towards unsupervised topic modeling and controllable text generation (CTG). It employs two continuous latent spaces with the conditional dependency between them for topic and sequence modeling. The model builds the sequence latent space with a series of flexible Householder process to create plausible content. |
2022 
|
[J1]
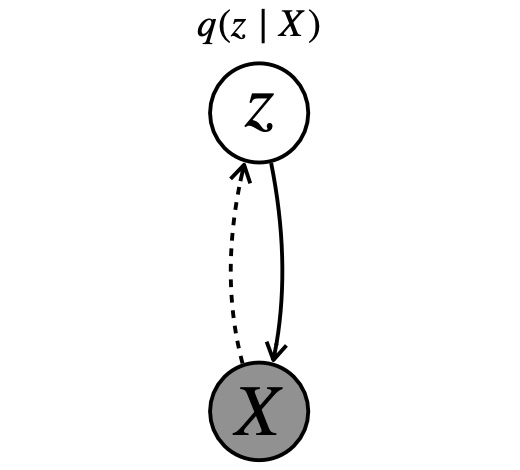
Haoqin Tu, Zhongliang Yang, Jinshuai Yang, Siyu Zhang, Yongfeng Huang KBS'22. Knowledge-Based Systems paper / code A model-agnostic framework towards flexible, semi-supervised and controllable text generation. This framework is “plug-and-play” with partial parameters to be fine-tuned in the pre-trained model. |
|
[P1]
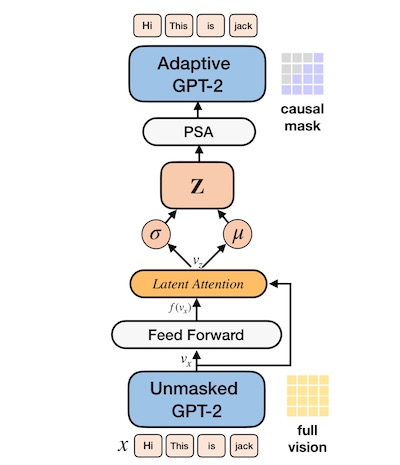
Haoqin Tu, Zhongliang Yang, Jinshuai Yang, Siyu Zhang, Yongfeng Huang Arxiv (Submitting to TASLP) arxiv / code The first big VAE model with adaptive parameter-efficient PLMs that can be optimized with minimum trainable parameters. Latent Attention is proposed to better construct latent spaces in VAE from the transformer encoder. AdaVAE achieves competitive performances in language modeling and low-resource classification with only 14.66% parameter activated. |
|
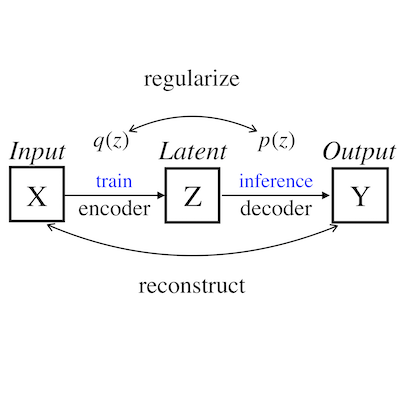
[P2]
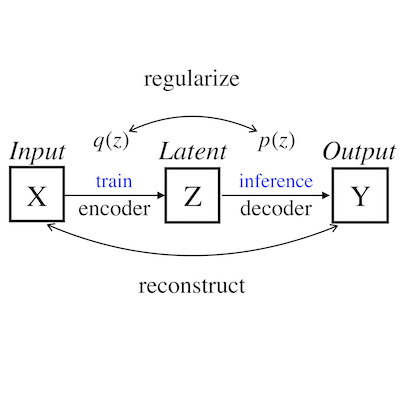
Haoqin Tu, Yitong Li Arxiv arxiv / paper list / Chinese blog This survey gives an introduction into existing generation schemes and problems associated with text auto-encoders, a review of several applications about controllable generation that are instantiations of these general formulations, as well as a discussion for future research. |
|
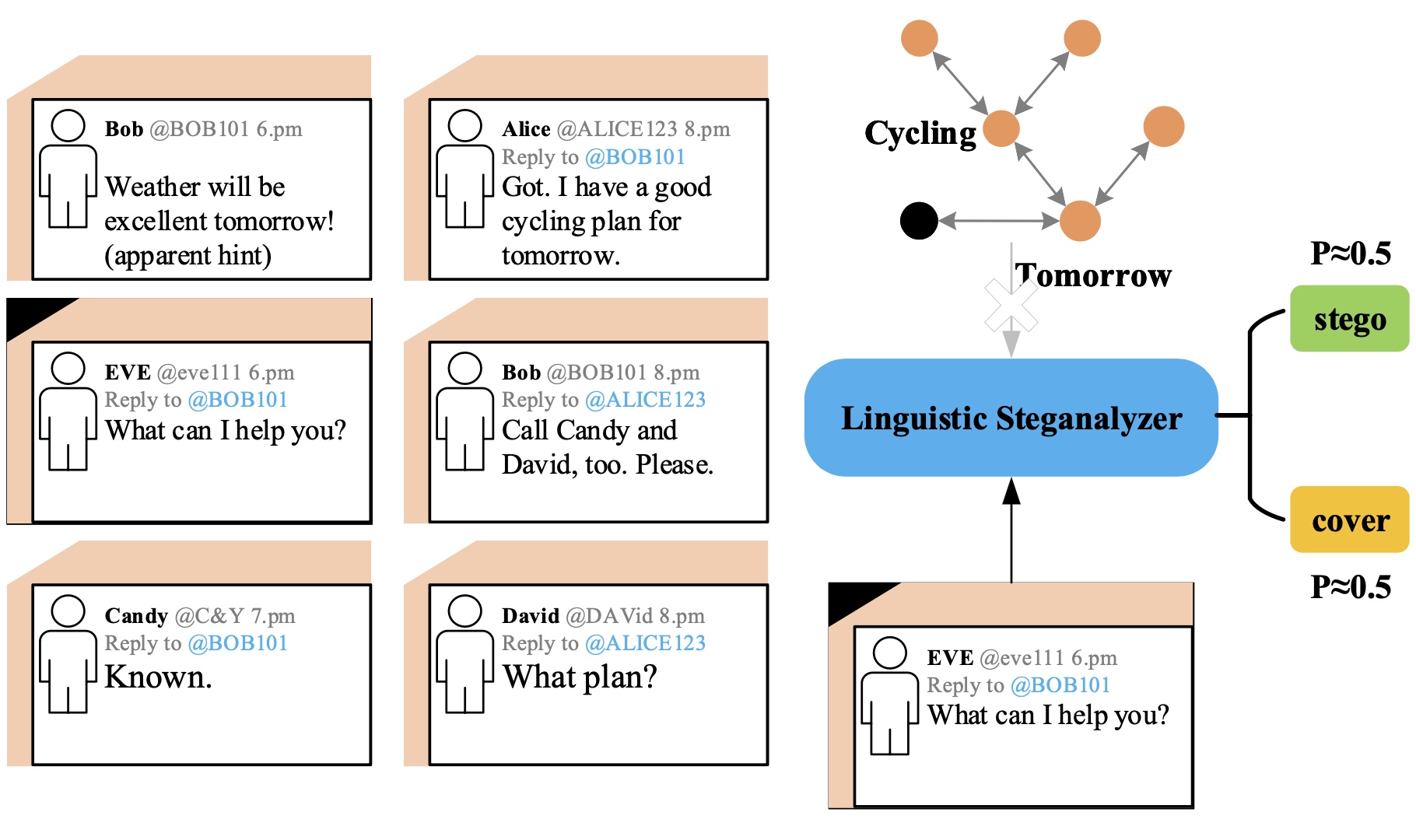
[J2]
Jinshuai Yang, Zhongliang Yang, Jiajun Zou, Haoqin Tu, Yongfeng Huang T-IFS'22. IEEE Transactions on Information Forensics and Security IEEE Xplore / code A dataset called Stego-Sandbox to simulate the real social network scenarios and an effective linguistic steganalysis framework integrating linguistic features and context features. |
|
|

|
Sep. 2024 - Present, VLAA Lab, UC Santa Cruz , Ph.D. Student, Multimodal & AI Safety. |

|
Aug. 2021 - Jun. 2024, University of Chinese Academy of Sciences , M.Eng., NLG & Multimodal, Current GPA: 3.88/4.0. |

|
Jun. 2020 - Sep. 2022, NGNLab, Tsinghua University , Research Assistant, NLG & Latent Variable Models. |
|
|
|
|






|
thanks jon for the website template |